
Introduction
We discuss the Gated Convolutional Network, proposed by Dauphin et al. 2017, that models sequential data with a stack of 1D convolutional blocks.
Method
For input \(\pmb X\in\mathbb R^{N\times m}\), a sample of sequential data of size \(N\), each with \(m\) features, GCN applies a 1D convolution to it to capture sequential information between a filter. Despite the small size of a normal convolutional filter, we can still capture long-term dependencies through a hierarchy of convolutional layers. More importantly, convolutional layers open an opportunity to parallelism, reducing the number of operations from \(\mathcal O(N)\) for a traditional RNN to \(\mathcal O(N/k)\).
There are two things noteworthy when using convolution to model sequential data.
- To avoid the leak of future information. We pad the beginning of \(\pmb X\) with \(k-1\) zeros, where \(k\) is the filter size.
- Similar to LSTMs, we adopt a gated mechanism, namely Gated Linear Unit(GLU), to control what information should be propagated through the layer. No activation is further applied after GLU
The following code shows a gated convolutional layer in Tensorflow 2.x
g = tf.keras.layers.Conv1D(x, N, k, padding='causal', activation='sigmoid')
y = tf.keras.layers.Conv1D(x, N, k, padding='causal')
y = g * y
Experimental Results
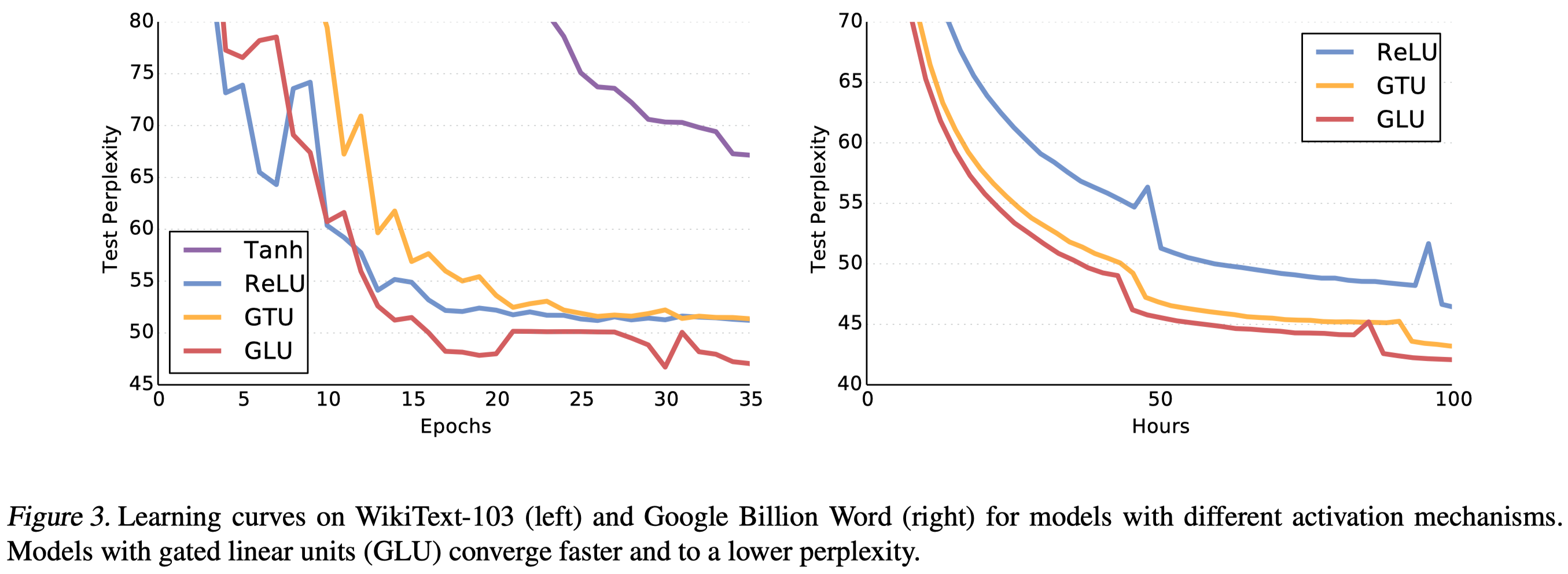
Figure 3 shows the effectiveness of GLU, where GTU(gated tanh unit) use an LSTM-style mechanism:
g = tf.keras.layers.Conv1D(x, N, k, padding='causal', activation='sigmoid')
y = tf.keras.layers.Conv1D(x, N, k, padding='causal', activation='tanh')
y = g * y
We can see that GLU converges to a lower perplexity than other methods on both datasets. Furthermore,
- Comparing tanh and GTU, we can see that the gating mechanism plays an important role in model capabilities. The result is consistent when comparing ReLU and GLU—ReLU can be regarded as \(\text{ReLU}(x)=x\cdot 1_{x>0}\).
- Comparing GTU and GLU, we can see that a linear path(without tanh) speeds up the learning process and results in better performance.
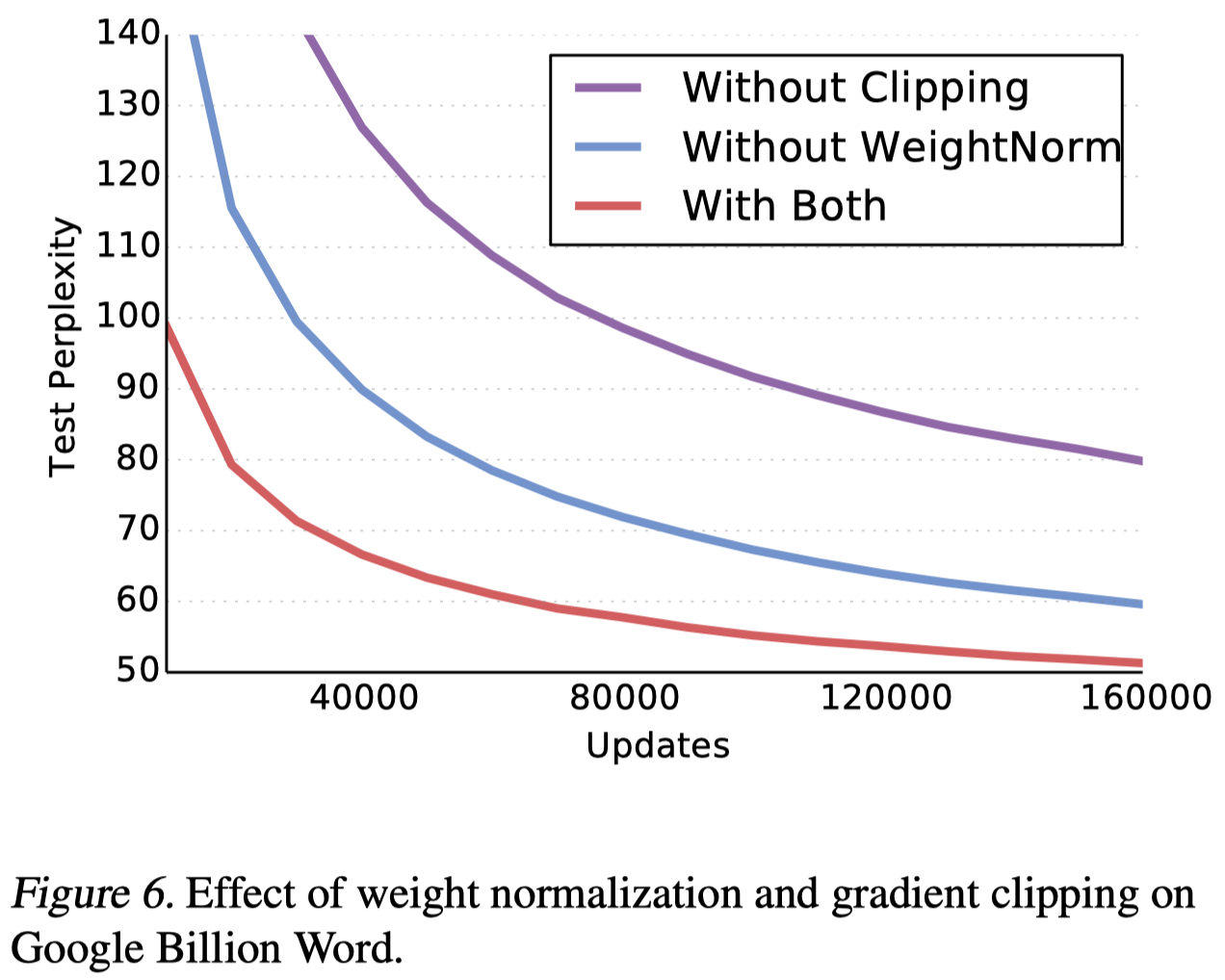
Figure 6 shows the effect of weight normalization and gradient clipping; both significantly speed up convergence.
References
Dauphin, Yann N., Angela Fan, Michael Auli, and David Grangier. 2017. “Language Modeling with Gated Convolutional Networks.” 34th International Conference on Machine Learning, ICML 2017 2: 1551–59.