
Introduction
We discuss MAPPO, proposed by Yu et al. 2021, which shows that PPO with some tricks can exhibit SOTA performance in multi-agent environments.
Common Tricks
MAPPO uses two separate networks for the policy and the value function. These networks are shared among all agents. The common practices in PPO implementation are used, including GAE with advantage normalization, observation normalization, gradient clipping, value clipping, layer normalization, and a large batch size under 1 GPU constraint.
More Tricks
Value Normalization

MAPPO adopts PopArt to normalize target values and denormalizes the value when computing the GAE. This ensures that the scale of the value remains in an appropriate range, which is critical for training neural networks. Yu et al. 2021 suggest always use PopArt for value normalization.
Noticeably, Yu et al. 2021 do not compare value normalization with reward normalization. Moreover, recent RL algorithms often use TBO to achieve the same effect.
Agent-Specific Global State

MAPPO uses a concatenation of the local feature and the global state as the input to the value function. Yu et al. 2021 argue that local observations contain many agent-specific features, such as agent id, available actions, and relative distances to enemies and teammates, that are not in the global state.
It is important to monitor the final feature size as a large feature vector may make the value learning substantially more challenging. A large value network may come in handy for a large feature vector.
Training Data Usage
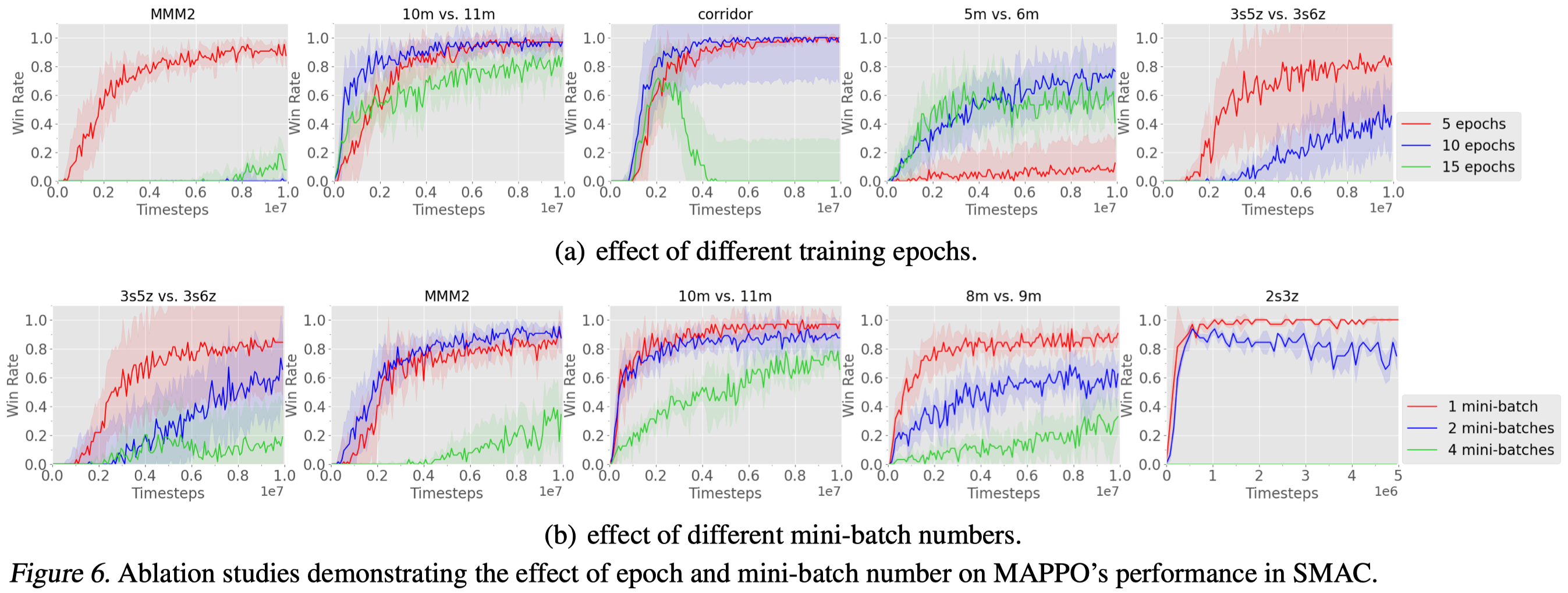
Yu et al. 2021 find that more epochs or more mini-batches often hurt the performance and suggest using a small number of epochs with a single minibatch per iteration.
Action Masking
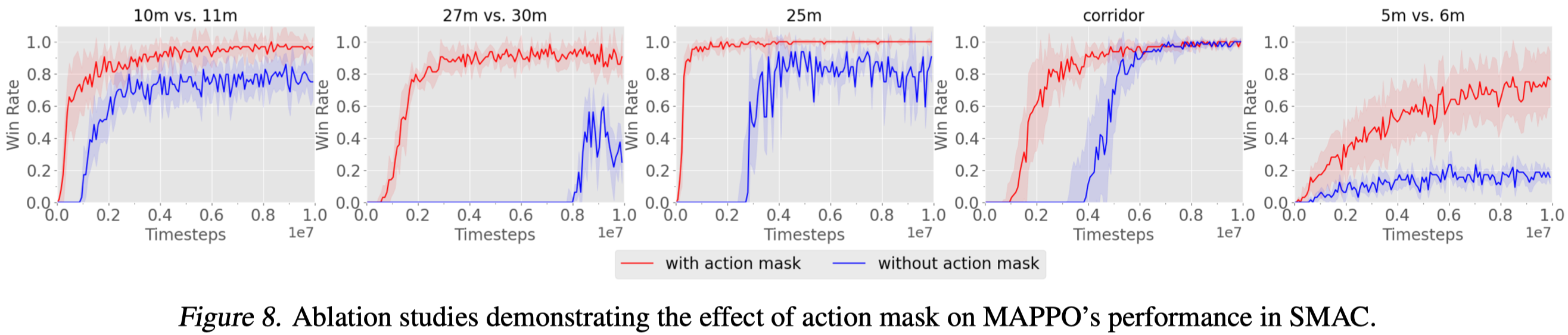
Oftentimes, some actions cannot be executed due to game constraints. So, when computing the logits for the softmax action probability \(\pi(a_i\vert o_i)\), we mask out the unavailable actions in both the forward and backward pass so that the probabilities for unavailable actions are always zero.
Action mask can be done by 1) setting the associated logits to a very small value(e.g, \(-10^{10}\)); 2) remove unavailable actions from the action space if these actions are not available to the agent throughout its lifetime.
Death Masking
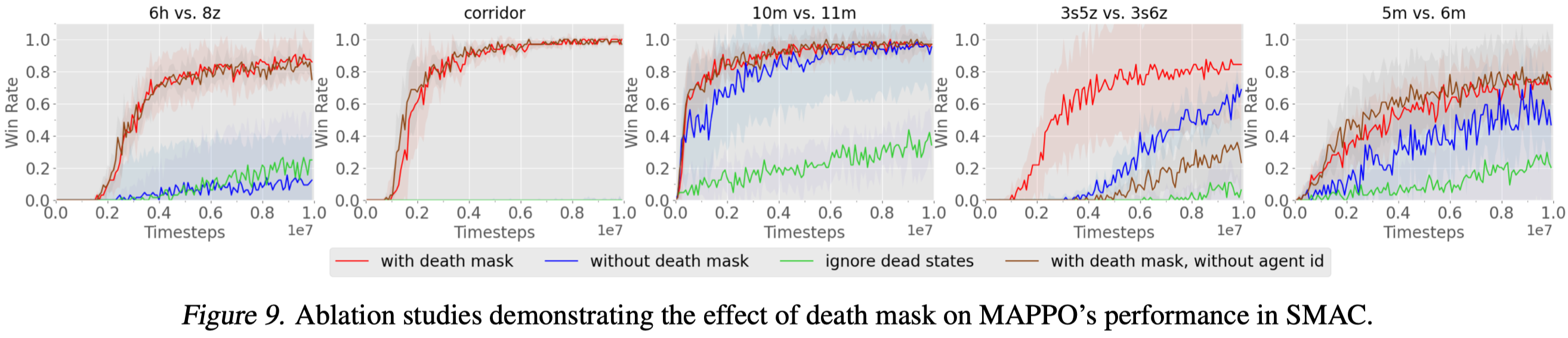
In multi-agent games, an agent may die before the game terminates but the value learning can still be performed in the following time steps. In games such as SMAC, after the agent dies, the agent-specific features become zero, while the global state remains non-zero. As a result, a combination of the agent-specific features and the global state for a dead agent exhibits a drastic distribution compared to that for a living agent. Training the value network with these out-of-distribution data can thus be harmful. Yu et al. 2021 experimentally find it better to use a zero vector with the agent ID as the input to the value function after the agent dies. Note that although the zero vector with the agent ID is still out of the feature distribution for living agents, it provides a consistent representation that captures the state at which an agent is dead, which may make it easier for value learning.
References
Yu, Chao, Akash Velu, Eugene Vinitsky, Yu Wang, Alexandre Bayen, and Yi Wu. 2021. “The Surprising Effectiveness of MAPPO in Cooperative, Multi-Agent Games.” http://arxiv.org/abs/2103.01955.