
Introduction
We talk about a distributed reinforcement learning architecture for Q-learning methods, which separates data collection from model iteration, thereby achieving very high throughput.
Ape-X
The idea behind Ape-X is simple: It decouples the learning from actor, wherey allowing a central replay used only by learner to employ prioritized experience replay. Another benefit is that it allows multiple actors collect data in parallel(may with different exploration strategies), which ensures both recency and diversity of data in the buffer. The architecture in a nutshell is well illustrated in the following figure
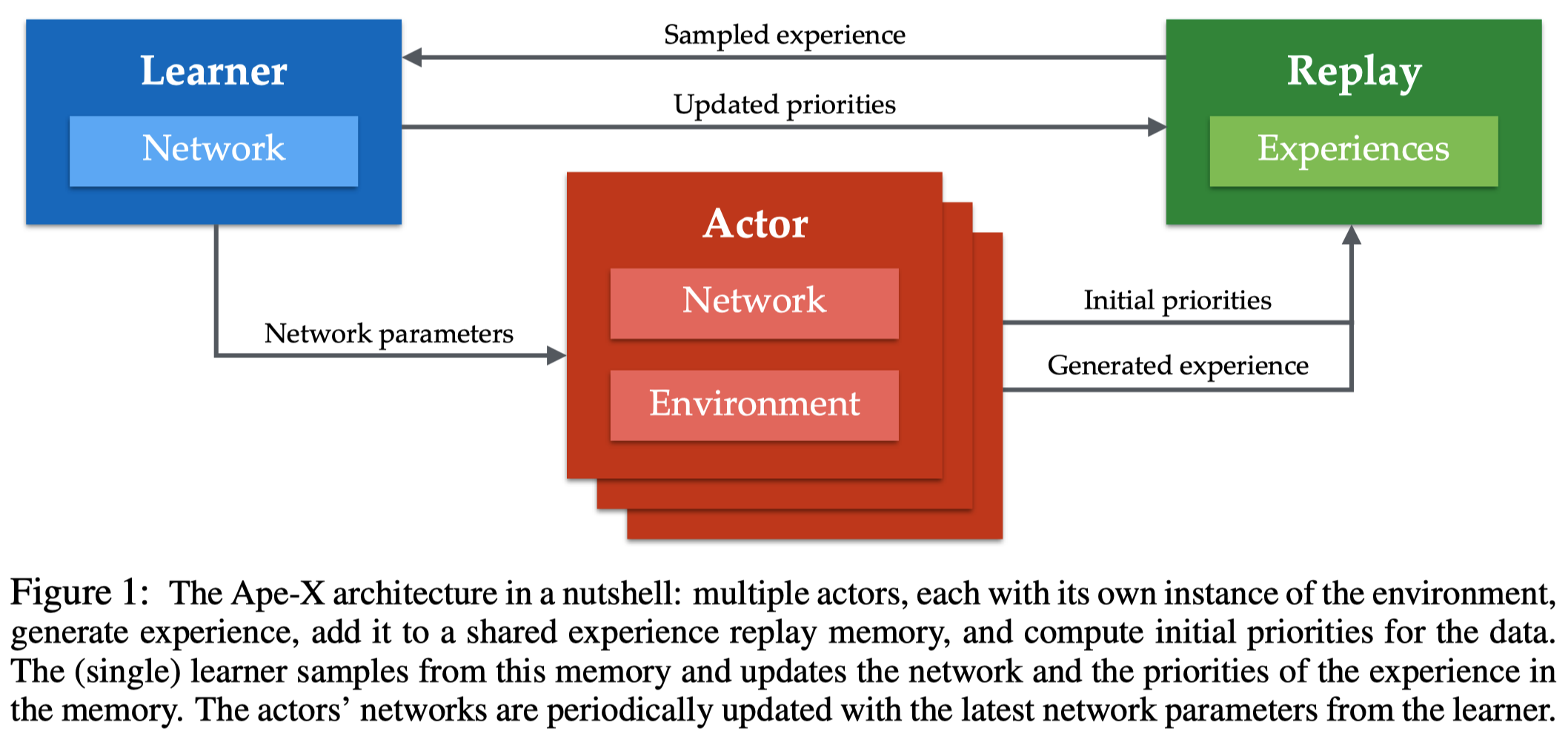
The learning algorithm in general follows \(Q\)-learning style so that it can perform off-policy update. The detailed algorithm is described as follows
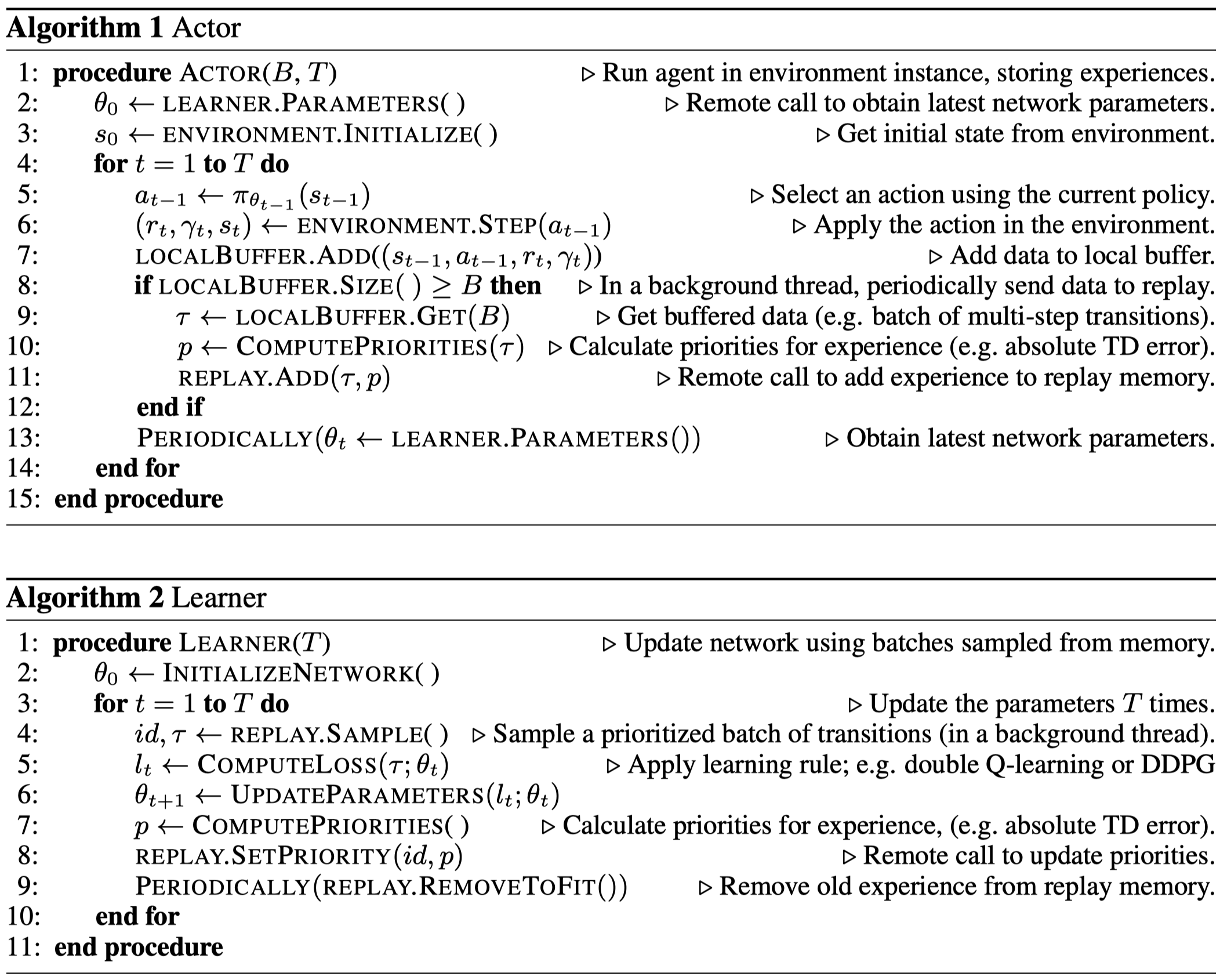
Several things worth to be noted:
- The priorities are computed in each actor using local \(Q\)-values before sending data to the central replay, different from the original prioritized DQN, which initializes the priorities of new transitions to the maximum priority seen so far. This is because the original method would result in a myopic focus on the most recent data when there are a large number of actors
- Local buffer also stores \(Q_t\) and \(Q_{t+n}\), which later will be used to compute priorities and discarded afterwards. This, however, is not necessary when combining Ape-X with DDPG-style algorithms, since the latter ones do not need to compute \(Q\)-functions when interacting with the environment.
References
- Dan Horgan et al. Distributed Prioritized Experience Replay