
Introduction
We briefly discuss a reinforcement learning agent, proposed by OpenAI et al., that solves Rubik’s Cube with a robot hand. In a nutshell, the agent is trained using a distributed training framework called Rapid with PPO in simulation. To improve the transferability from simulation to a real robot hand, OpenAI et al. design an curriculum algorithm called automatic domain randomization(ADR), which automatically adjusts domain randomization degree based on the agent’s current performance.
Policy Training (Section 6)
Task
OpenAI et al. uses a software library called Kociemba solver to plan a solution sequence, which reduces the task complexity for the RL agent. Therefore, the task now is to sense the state of the Rubik’s cube and control the robot hand to perform desired actions. In order to do so, two types of subgoals are defined: A rotation corresponds to rotating a single face of the cube by \(90\) degreess in the clockwise or counter-clockwise direction. A flip corresponds to moving a different face of the Rubik’s cube to the top. In practice, the agent is only asked to rotate the top face as it’s found to be far simpler than rotating other faces.
Actions, Rewards, and Goals
Actions: OpenAI et al. use a discretized action space with 11 bins per actuated joint. As a result, a multi-categorical distribution is used to produce the resulting actions.
Rewards: There are three types of rewards: (a) The difference between the previous and the current distance of the system state from the goal state. (b) an additional reward of \(5\) whenever a goal is achieved. (c) a penalty of \(-20\) whenever a cube block is dropped.
Goals: Random goals are generated during training. For the Rubik’s cube, goals are generated depending on the state of the cube at the time when the goal is generated. If the cube faces are not aligned, then the goal is to align the face and rotate the whole cube to a random orientation(called a flip). Alternatively, if the cube faces are aligned, the goal is to rotate the top cube face with \(50\%\) probability either clockwise or counter-clockwise. Otherwise, the goal is again perform a flip. Note that the cube faces are all aligned when we can rotate any faces without a hitch.
Episodic termination: A training episode is considered to be finished whenever one of the following conditions is satisfied: (a) the agent achieves 50 consecutive successes, (b) the agent drops the cube, (c) or the agent times out when trying to reach the next goal. Time out limits are \(800\) timesteps for the Rubik’s cube
Architecture
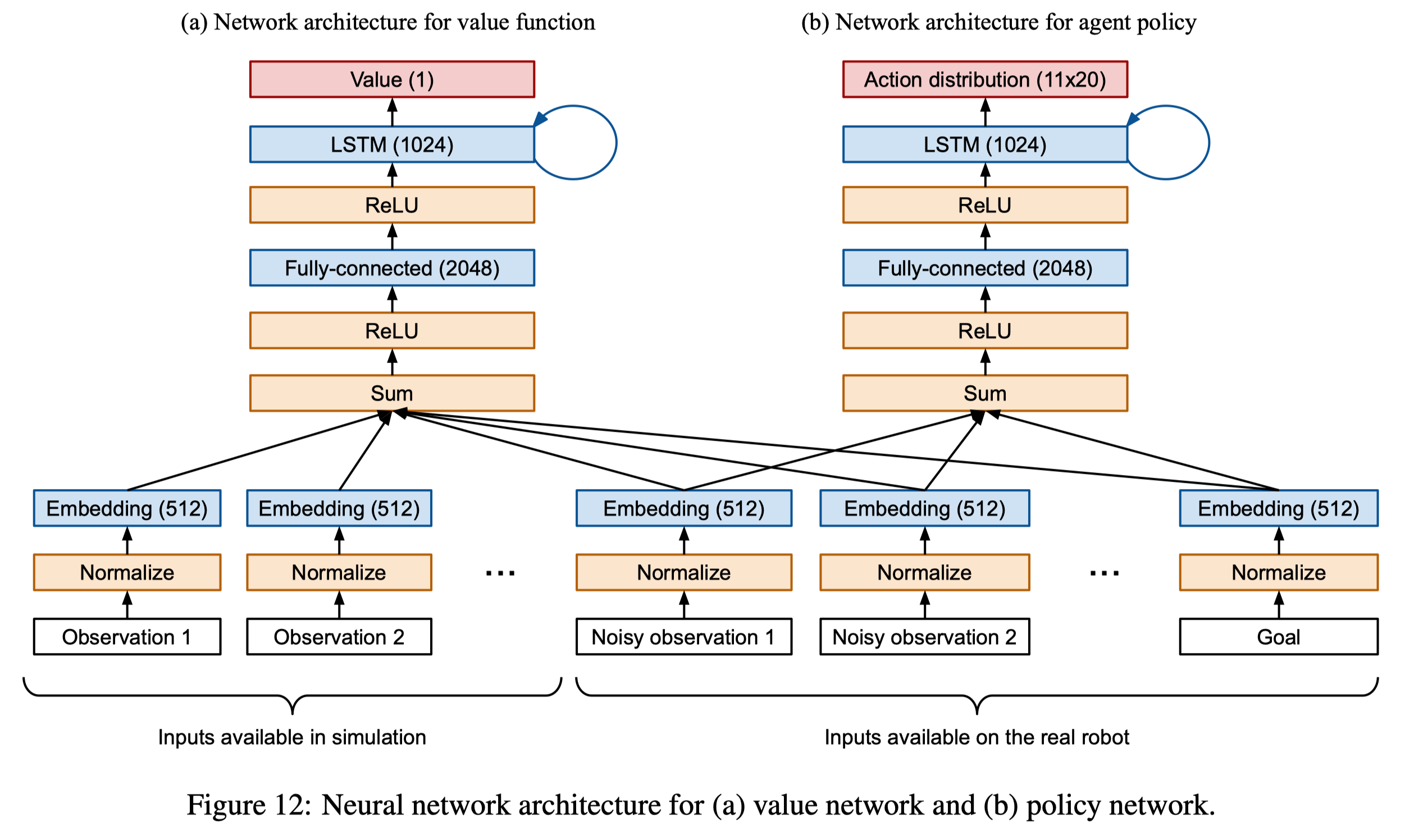
OpenAI et al. use their distributed training framework Rapid to train PPO on simulation. In particular, they use Asymmetric Actor-Critic architecture, in which the policy network receives noisy features while the value network receives both noisy and non-noisy features. Figure 12 describes the network architecture, where Noisy observations come from a ResNet50 trained via supervised learning. For details of supervised learning setup, we refer interested readers to Section 7 of the original paper.
For fast iteration, whenever the architecture changes, the new agent is first trained via behavior cloning(DAGGER, specifically) to learn from the previously trained agent.
Automatic Domain Randomization (Section 5)
The main hypothesis that motivates ADR is that training on a maximallly diverse distribution over environments leads to transfer via emergent meta-learning. More concretely, if the model has some form of memory(e.g., an LSTM), it can learn to adjust its behavior during deployment to improve performance on the current environment over time, i.e., by impelementing a learning algorithm internally. OpenAI et al. hypothesize that this happens if the training distribution is so large that the model cannot memorize a special-purpose solution per environment due to its finite capacity. In order to facilitate the learning process of such a large training distribution, OpenAI et al. propose ADR to adjust the diversity of the training data to provide curriculum learning. We discuss ADR in the remaining of this section in details.
Algorithm
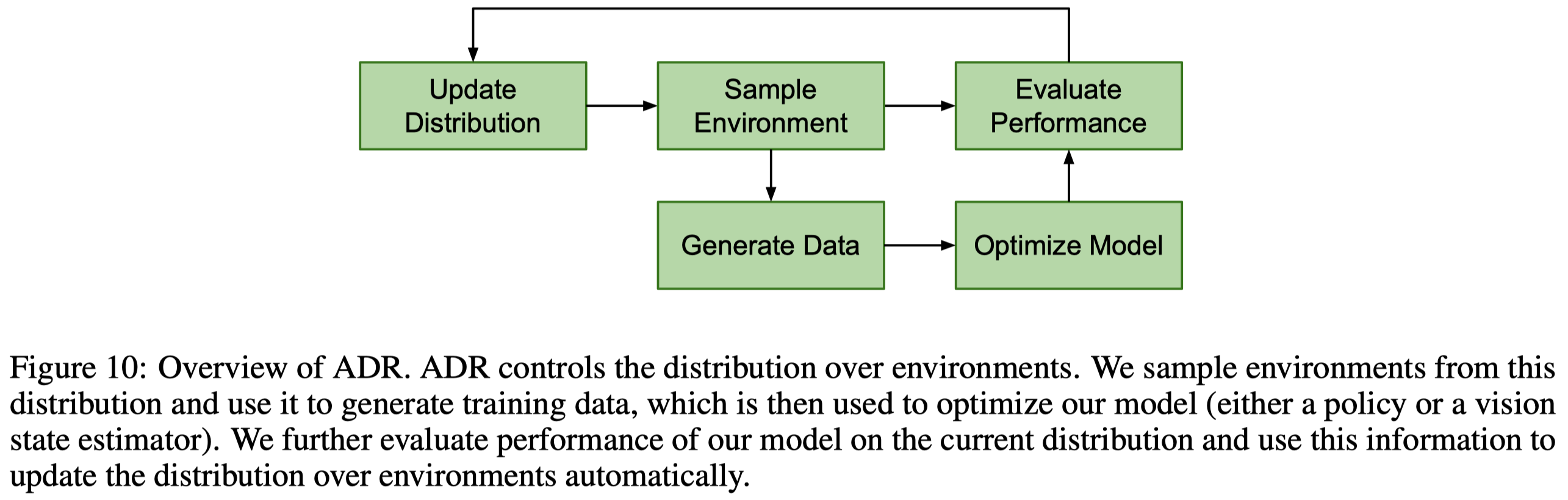
Overview
The agent starts training on a single environment. When it performs well, ADR expands the distribution over environments to the extend that the agent can still perform well, shrinks the distribution if otherwise. ADR provides a curriculum that gradually increases difficulty as training progresses, freeing from manually tuning the randomization. These benefits are non-trivial: as the curriculum process facilitates learning, the agent is now possible to manage a wilder distribution than it is under manual domain randomization.
Algorithm 1 demonstrates the workflow of ADR and Algorithm 2 describes the data generation process. Each worker executes Algorithm 1 with probability \(p_b\) and Algorithm 2 with probability \(1-p_b\).

Performance Threshold
A performance threshold is required to decide if a environment distribution is desirable. For RL training, they are configured as the lower and upper bounds on the number of successes in an episode. For vision training, they are the percentage of samples which achieves some target performance thresholds for each output(e.g., position, orientation). If the resulting percentage is above the upper threshold or below the lower threshold, the distribution is adjusted accordingly.
Environment Randomization
For each environment parameter \(\lambda_i\) we can randomize in simulation, we sample it from a uniform distribution \(P_\phi(\lambda)=U(\phi_i^L,\phi_i^H)\), where \(\phi_i^L,\phi_i^H\) are parameters that change dynamically with training progress. At each ADR step, we randomly sample a \(\lambda_i\) and fix it to a boundary value(\(\phi_i^L\) or \(\phi_i^H\)). Other environment parameters are sampled uniformly from \(P_\phi(\lambda)\). Then we evaluate the model performance. If the models perform better than the upper bound, we increase the distribution boundary; if the models perform worse than the lower bound, we decrease the distribution boundary.
References
- OpenAI, Marcin Andrychowicz, Bowen Baker, Maciek Chociej, Rafał Józefowicz, Bob McGrew, Jakub Pachocki, Arthur Petron, Matthias Plappert, Glenn Powell, Alex Ray, Jonas Schneider, Szymon Sidor, Josh Tobin, Peter Welinder, Lilian Weng, Wojciech Zaremba. Learning Dexterous In-Hand Manipulation
- <a name=”openai2019b’></a>OpenAI, Ilge Akkaya, Marcin Andrychowicz, Maciek Chociej, Mateusz Litwin, Bob McGrew, Arthur Petron , Alex Paino, Matthias Plappert, Glenn Powell, Raphael Ribas, Jonas Schneider, Nikolas Tezak , Jerry Tworek, Peter Welinder, Lilian Weng, Qiming Yuan, Wojciech Zaremba, Lei Zhang. Solving Rubik”s cube with a Robot Hand