Introduction
Traditional scalable reinforcement learning framework, such as IMPALA and R2D2, runs multiple agents in parallel to collect transitions, each with its own copy of model from the parameter server(or learner). This architecture imposes high bandwidth requirements since they demand transfers of model parameters, environment information etc. In this post, we discuss a modern scalable RL agent called SEED(Scalable Efficient Deep-RL), proposed by Espeholt et al. 2019 that utilizes modern accelerators to speed up both data collection and learning process and lower the running cost(80% reduction against IMPALA measured on Google Cloud).
Architecture
Deficiency of Traditional Distributed RL
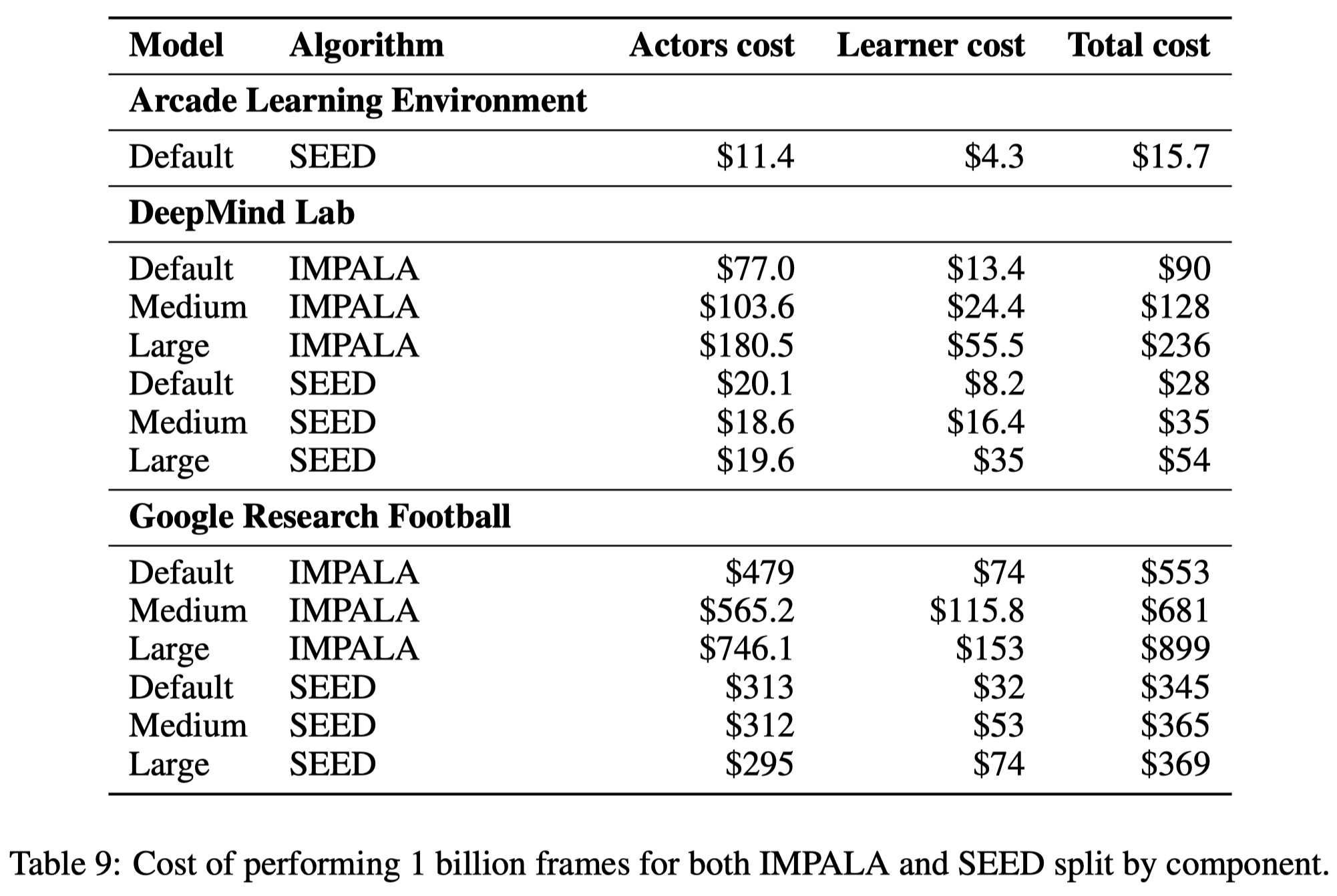
Here we compare SEED with IMPALA. The IMPALA architecture, which is also used in various forms in Ape-X, R2D2 etc., mainly consists of two parts: A large number of actors periodically copy model parameters from the learner, and interact with environments to collect trajectories, while the learner(s) asynchronously receives transitions from the actors and optimizes its model.
There are a number of reasons why this architecture falls short:
- Using CPUs for neural network inference: The actors usually use CPUs to do inference, which, however, are known to be computationally inefficient for neural networks.
- Inefficient resource utilization: Actors alternate between two tasks: environment steps and inference steps. The computation requirements for the two tasks are often not similar which leads to poor utilization or slow actors. For example, some environments are inherently single threading while neural networks are easily parallelizable
- Bandwidth requirement: Model parameters, recurrent states, and transitions are transferred between actors and learners which would introduce a huge burden to the network bandwidth.
Architecture of SEED
Seed is designed to solve the problems mentioned above. As shown in Figure 1b, inference and transitions collection are moved to the learner which makes it conceptually a single-machine setup with remote environments. For every single environment step, the observations are sent to the learner, which runs the inference and sends actions back to the actors(see Supplementary Materials for the latency issue)
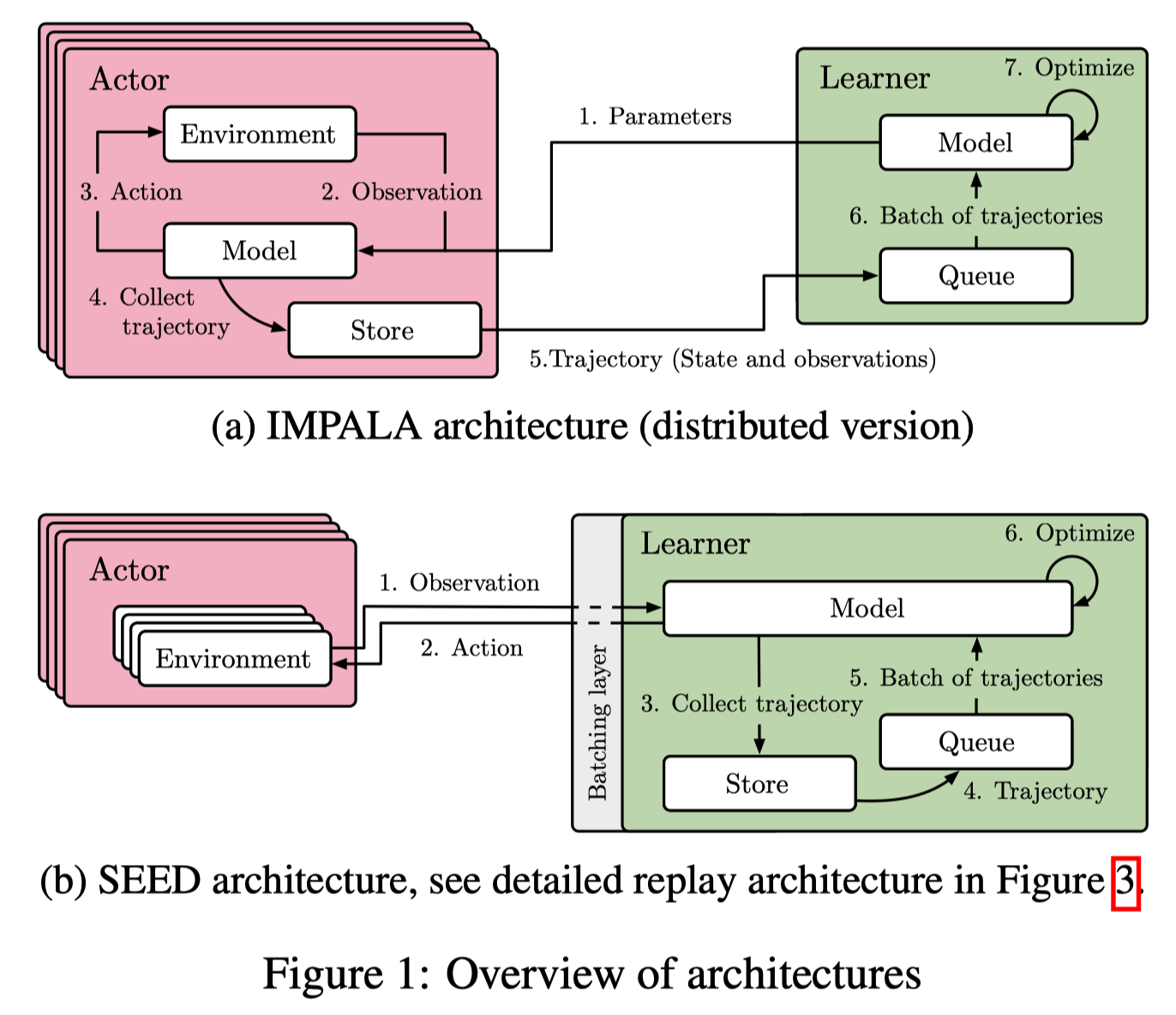
The learner architecture consists of three types of threads:
- Inference: Inference thread receives a batch of transitions(e.g., states, rewards, done signals) from different actors, loads corresponding recurrent states, and makes actions. The actions are then sent back to the actors while the latest recurrent states are stored.
- Data prefetching: When a trajectory is fully unrolled it is added to a FIFO queue or replay buffer and later sampled by data prefetching threads
- Training: The training thread takes the prefetched trajectories stored in device buffer, apply gradients using the training TPU(or GPU) host machines.
To reduce the idle time of actors, each actor runs multiple environments. Therefore, they are free to proceed with another environment when waiting for the action from the learner.
References
Espeholt, Lasse, Raphaël Marinier, Piotr Stanczyk, Ke Wang, and Marcin Michalski. 2019. “SEED RL: Scalable and Efficient Deep-RL with Accelerated Central Inference,” 1–19. http://arxiv.org/abs/1910.06591.
Supplementary Materials
Latency
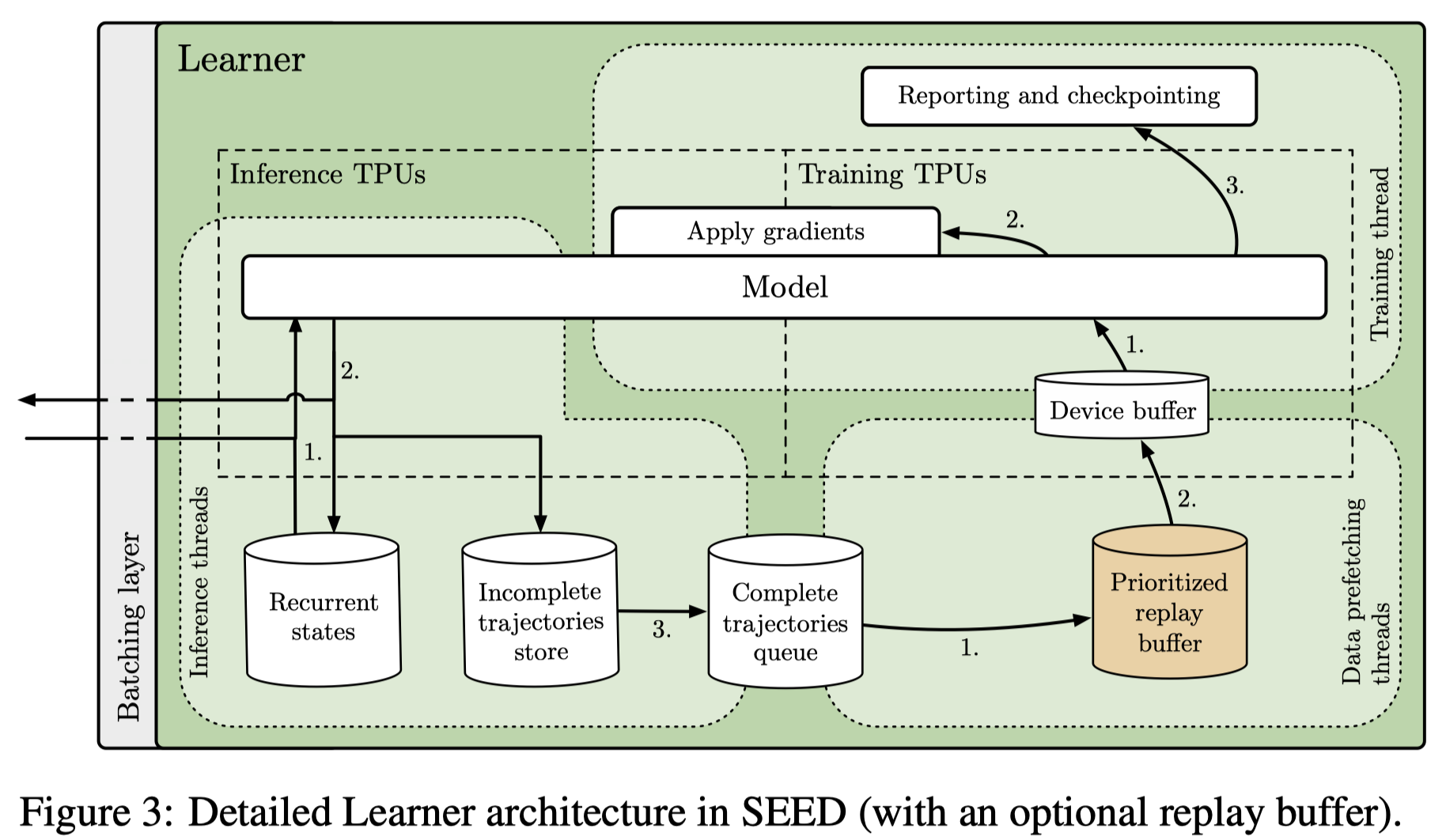
To minimize latency, Espeholt&Marinier&Stanczyk et al. created a simple framework that uses gRPC—a high-performance RPC library. Specifically, they employ streaming RPCs where the connection from actor to learner is kept open and metadata sent only once. Furthermore, the framework includes a batching module that efficiently batches multiple actor inference calls together. In cases where actors can fit on the same machine as learners, gRPC uses Unix domain sockets and thus reduces latency, CPU, and syscall overhead. Overall, the end-to-end latency, including network and inference, is faster for a number of the models we consider below
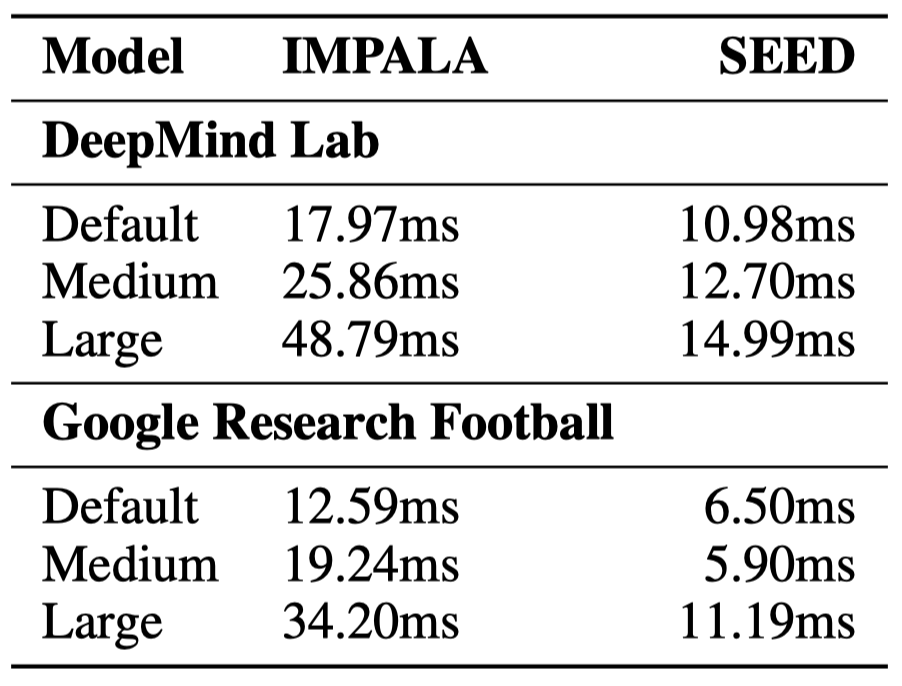
Cost Comparison