
Introduction
We discuss some interesting ideas from the 3rd-place team of MineRL 2019.
Network Architecture
Scheller et al. use a separate network architecture for value and policy functions. They use the same convolutional network as IMPALA. Non-spatial inputs are concatenated with the previous action and process by a two-layer MLP with \(256\) and \(64\) units. Then spatial and non-spatial representations are concatenated and fed into an LSTM cell with \(256\) units. As MineRL has a composed action space, each action is represented with an independent policy head on top of the LSTM output.
They also find it’s beneficial to include the inventory as additional input, processed by a separate dense two-layer network. This is reasonable as “craft” and “smelt” action relies on the current inventory.
Learning
The agent is first learned through imitation learning, and then fine-tuned using reinforcement learning. We sequentially discuss these two phases in the rest of this section.
Imitation Learning
Scheller et al. only trains the policy network \(\pi\) in this phase. They do not learn the value network \(V\) as the learned policy is very different from the demonstration.
Reinforcement Learning
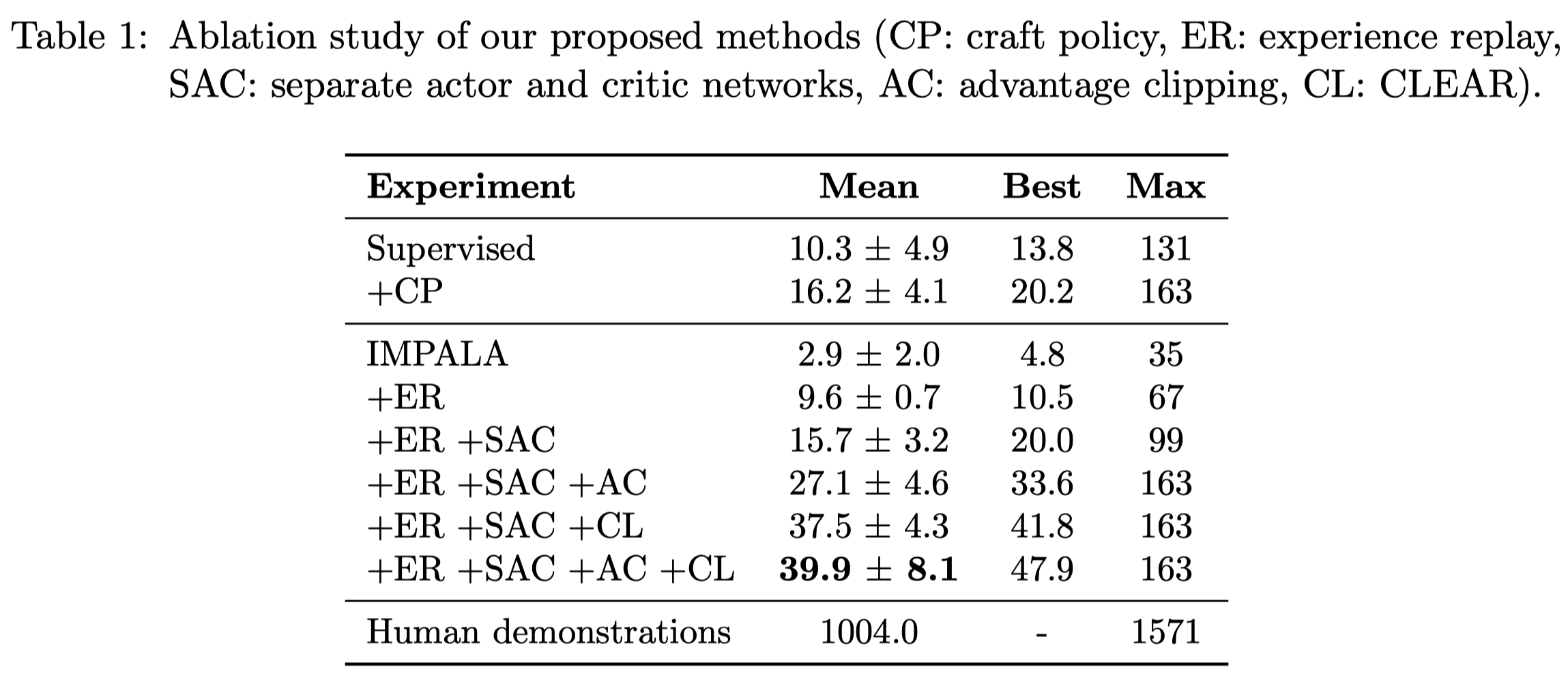
They employ IMPALA to improve the policy \(\pi\) and to approximate the value function \(V\). However, naively applying IMPALA causes exhibits collapsing performance. They propose several enhancements to prevent performance decline
- Using a replay buffer to mix the online experiences with previous experiences. Empirically ,they find \(15\) replay samples per online sample performs best.
- Using separate networks for the policy and value functions. This prevents the learning of value function interfere the policy. This is especially important as the value function is still primitive while the policy has learned previously.
- Clipping the negative advantages at zero. They find that policy obtained from imitation learning yield returns with high variance. As a result, there is a risk of erroneous value estimates wrongly discouraging desired behavior. Clipping advantage in the policy loss prevents such destructive updates and only reinforce better-than-expected trajectories.
- Employing CLEAR to prevent catastrophic forgetting and increase stability of learning. CLEAR utilizes experience replay and penalizes (1) the KL divergence between the historical policy distribution and the present distribution, (2) the L2 norm of the difference between the historical and present value functions
References
Scheller, Christian, and Manfred Vogel. 2020. “Sample Efficient Reinforcement Learning through Learning from Demonstrations in Minecraft,” no. 1: 1–10.