
Introduction
We discuss an agent developed by OpenAI et al. that exhibits several emergent strategies in hide-and-seek environment.
Environment
There are \(N\) agents interacting with each other in the environment. Each agent receives its own observation and reward every time step, and aims to maximize its total expected discounted return. The reward is team based; hiders are given a reward of \(1\) if all hiders are hidden and \(-1\) if any hider is seen by a seeker. Seekers are given the opposite reward. An additional reward of \(-10\) is given if agents go too far outside the play area to confine the agent behavior to a reasonable space. An episode lasts 240 time steps, the first \(40\%\) of which are the preparation phase where all agents are given zero reward.
Method
The agent is based on PPO, GAE, LSTM, rapid, and self-play. Both hider and seeker share the same actor-critic model.
Input Preprocessing
Advantage targets are z-scored over each buffer before each optimization step. Observations and value function targets are z-scored using a mean and variance estimator that is obtained from a running estimator with decay parameter \(1-10^5\) per optimization substep. Notice that we normalize the value function targets instead of rewards here.
Optimization Setup
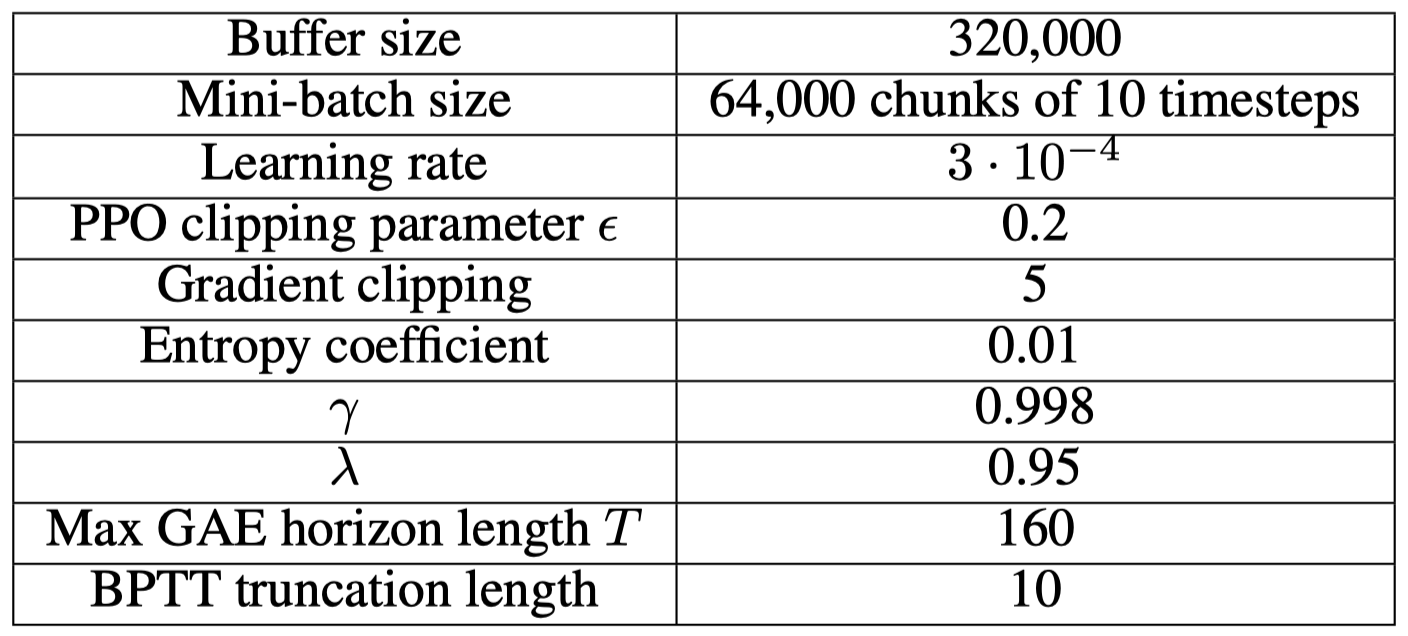
Training is performed using the distributed rapid framework, which interleaves data collection with optimization steps. Rollouts are first collected using the current parameters. Then they are cut into windows of \(160\) timesteps and reformatted into \(16\) chunks of \(10\) timesteps(the BPTT truncation length), which results in \(320,000\) chunks in the training buffer. Each optimization step consists of \(60\) SGD substeps using Adam with mini-batch size of \(64,000\) chunks. We perform at most \(4\) optimization steps for each rollout.
Architecture
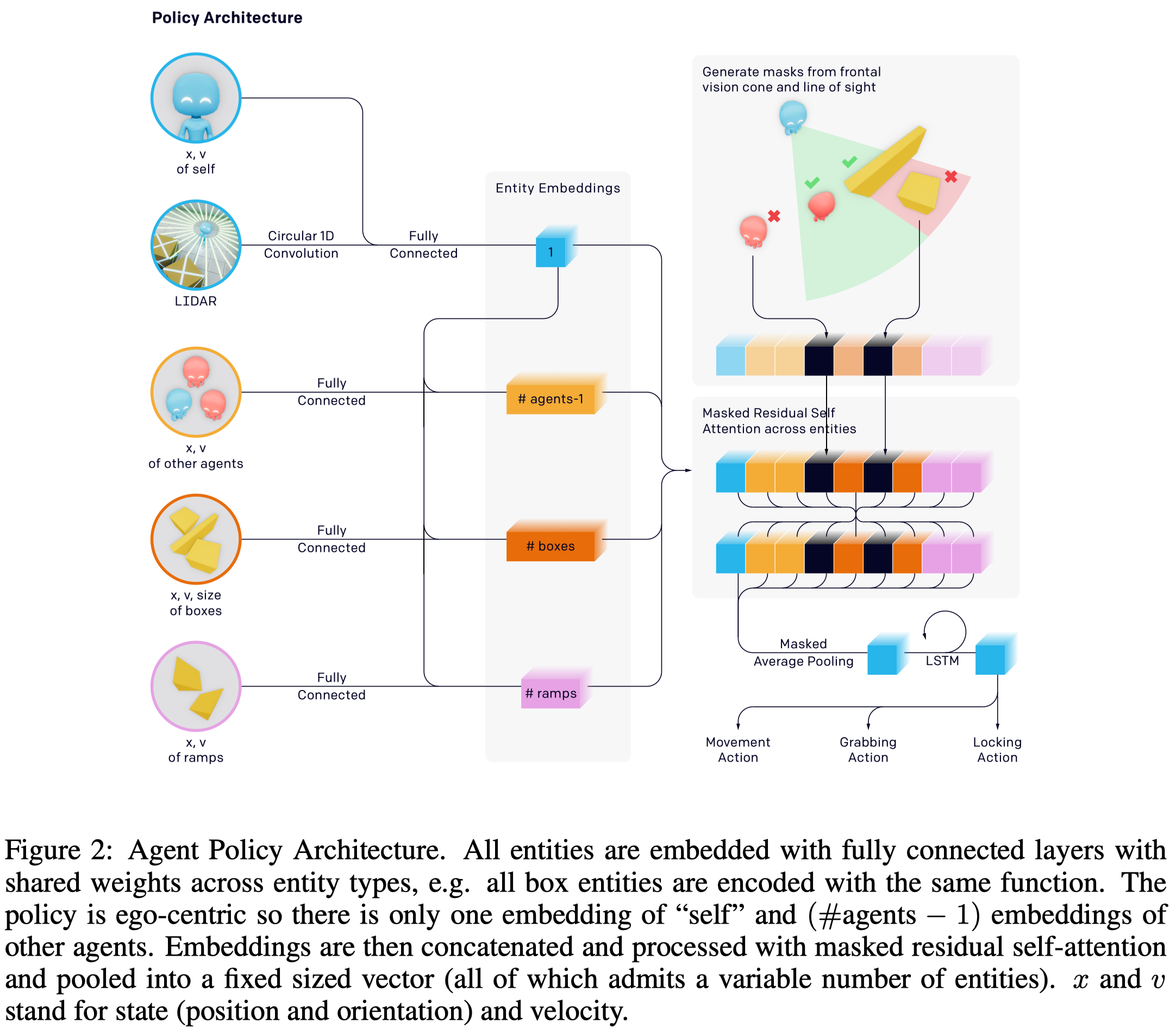
The policy architecture adopted here consists of three parts:
- Encoders. The lidar observations are first passed through a circular 1D-convolution and concatenated onto the agent’s representation of self, \(x_{self}\). Other objects are concatenated with \(x_{self}\) and then embedded with a dense layer where parameters are shared between objects of the same type.
- Masked residual self-attention. All the embedded entities are passed through a masked residual self-attention in the form of \(y=\text{dense}(\text{self-attention}(x))+x\), with masks filter out-of-sign objects. The outputs are average-pooled along the entity dimension with masks and again concatenated to \(x_{self}\).
- LSTM and action heads. The final representation is passed through another dense layer and an LSTM before pulling off separate action heads.
The value function uses a similar network structure but it has access to the full environment state without any information masked due to visibility.
Interesting Experimental Results
Six Emergent Phases

Scale Plays a Critical Rule in Learning

By defaults, the agent is trained with mini-batch size of \(64,000\). OpenAI et al. found larger batch sizes lead to much quicker training time, which reduces the number of required training steps, while only marginally affecting sample efficiency down to a batch size of \(32,000\). On the other hand, experiments with batch sizes of \(16,000\) and \(8,000\) never converged
A.2 Dependence of Skill Emergence on Randomness in the Training Distribution of Environments

Open AI et al. 2019 found a relationship between environment randomness and skill emergence: As the amount of randomness is reduced, fewer stages of skill progression emerges, and with at times less sophisticated strategies (e.g., hiders learn to run away and use boxes as moveable shields)
Comparison to Intrinsic Motivation
Open AI et al. 2019 compare behaviors learned in hide-and-seek to two intrinsic motivation methods: count-based exploration and RND. They found the agent learned in multi-agent setting exhibits more human-interpretable behavior
Transferability
In order to evaluate agent’s capabilities, OpenAI et al. 2019 experiments several benchmark intelligence tests that use the same observation and action spaces as hide and seek. They examine whether pretraining agents in hide and seek and then fine-tuning them on the evaluation suite leads to faster convergence or improved overall performance. For all tasks, fine-tuning only happens at the final dense layer and layernorm for both the policy and value networks. The experiments shows the agent transfer well on some tasks, e.g., navigation tasks, but fails on the others. These results implies that the agent’s learning skill representations are entangled and difficult to fine-tune. Similar experiments were conducted at different stage of emergence, they found the agent’s memory improves through training as indicated by performance in the navigation tasks; however, performance in the manipulation tasks is uncorrelated, and performance in object counting changes seems transient; it performed well during phase 1 but lost this ability in the later phase.
References
Baker, Bowen, Ingmar Kanitscheider, Todor Markov, Yi Wu, Glenn Powell, Bob McGrew, and Igor Mordatch. 2019. “Emergent Tool Use From Multi-Agent Autocurricula.” http://arxiv.org/abs/1909.07528.